We are facing the above issue on a regular basis. We have managed to narrow the cause down to it happening when we have the timeout parameter set on the Redis server.
When this is set (to 600s), we periodically get this exception from any client that is connected to it. We presume that its caused by the client going to use a connection from the pool which has been closed by the server which then causes a socket send/receive exception.
The issue is that we do need this on as otherwise the redis server is getting slowly swamped with dead connections.
All our clients are running on linux containers.
Any suggestions to making this work?
Stack Trace Below:
"StackTraceString": [
" at ServiceStack.Redis.RedisNativeClient.SendReceive[T](Byte[][] cmdWithBinaryArgs, Func`1 fn, Action`1 completePipelineFn, Boolean sendWithoutRead) in /home/runner/work/ServiceStack/ServiceStack/ServiceStack.Redis/src/ServiceStack.Redis/RedisNativeClient_Utils.cs:line 733
at ServiceStack.Redis.RedisClient.<>c__DisplayClass462_0`1.<Get>b__0(RedisClient r) in /home/runner/work/ServiceStack/ServiceStack/ServiceStack.Redis/src/ServiceStack.Redis/RedisClient.ICacheClient.cs:line 49
at ServiceStack.Redis.RedisClient.Exec[T](Func`2 action) in /home/runner/work/ServiceStack/ServiceStack/ServiceStack.Redis/src/ServiceStack.Redis/RedisClient.ICacheClient.cs:line 31
Can you share your Redis config regarding the timeout? And also your AppHost config when registering your Redis Client Manager into your IoC container including connection string if you are using it (minus any sensitive info)? Are you use a managed Redis service like Azure or other cloud host? Also what version of Redis and ServiceStack you are running too please.
It sounds like the pooled clients are configured at the app level for a 10 second timeout and your Redis instance has a longer one? If you can provide the info requested above it will help clear up your setup and what the can be changed to resolve.
Thanks for the quick reply. We have a 3-node internal setup here using Sentinel. We do not have any specific connection strings, other than pointing the Pool Manager to the sentinel hosts. Please see below:
private IRedisClientsManager SetupConnection()
{
Licensing.RegisterLicense(_licenseKey);
var servers = Environment.GetEnvironmentVariable("Redis.Servers").Split('|');
var useSentinel = !string.IsNullOrEmpty(Environment.GetEnvironmentVariable("Redis.Use.Sentinel"));
_logger.Information("Connecting to [{0}]", servers);
//TODO This should be extracted into our own logging interface.
LogManager.LogFactory = new SerilogFactory();
if (useSentinel)
{
var sentinel = new RedisSentinel(servers);
sentinel.RedisManagerFactory = (master, replicas) => new RedisManagerPool(master, new RedisPoolConfig
{
MaxPoolSize = _maxPoolSize
});
return sentinel.Start();
}
else
{
return new RedisManagerPool(servers, new RedisPoolConfig
{
MaxPoolSize = _maxPoolSize
});
}
}
In terms of versions, we are running Redis 6.2.5, and ServiceStack 6.1.0
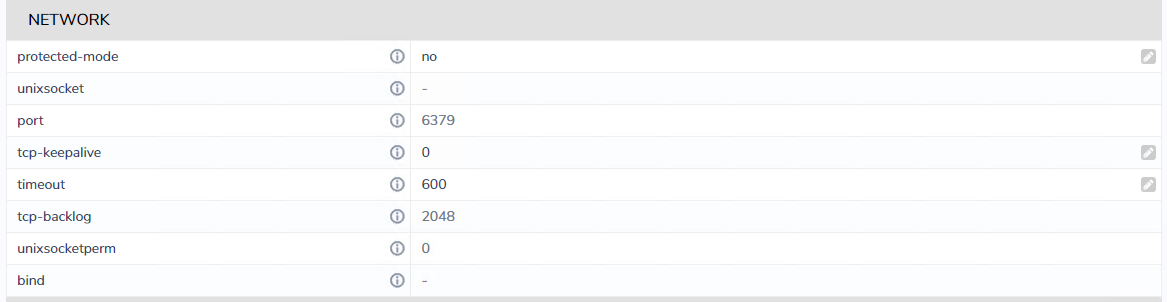
Below is a screenshot of the Redis config, its the Timeout line that causes / stops this behaviour
Let us know if that solves the issue, but would also look at production loads at the time of these errors in your logs to see what command(s) are producing this heavy loads or if quiet another cause like network issues?
the thing is, if i change the timeout on redis from 600 to 0, i.e disables stale connections from being dropped, the errors stop straight away. As soon as i enable it again, they come back.
Is it possible there is a static or instance of a Redis client that is getting stuck open after you’ve finished using it? Are you able to monitor active connections overtime in your instance, (eg if it is a managed service, see stats in something like AWS CloudWatch or Azure?) to see if there is anything unexpected when it comes to connected clients?
Have you had your ServiceStack server running in debug mode when the problem has occurred? There might be some additional information logged related to the retries that might clear things up.
Having zombie connections typically indicates redis clients aren’t always being disposed. Have a look at Redis Troubleshooting for how to assert that Redis connections are only accessed from the same thread where it was retrieved from the pool.
If you change Redis server timeout you’ll also need to change the IdleTimeout to have a lower value than Redis Server, however it already has a default value of 240s which is already lower than 600s:
RedisConfig.DefaultIdleTimeOutSecs = 240;
The other configuration that will have an effect is increasing the Retry Timeout used in Automatic Retries which specifies how long it should attempt to reconnect to the Redis server before failing with the Exceeded Timeout Exception, e.g:
RedisConfig.DefaultRetryTimeout = 30 * 1000;
Incase trying to connect is hanging the client, you may want to specify a connection timeout so the client is able to auto retry before exceeding the RetryTimeout, e.g:
RedisConfig,DefaultConnectTimeout = 10 * 1000;
Redis Stats may provide some insight, but this captures overall stats, not what’s wrong with a single client:
RedisStats.ToDictionary().PrintDump();
Enabling logging may also provide a bit more context around the failed auto connection retry.
When the Exception does throw can you see if you can get the state of the client, specifically LastConnectedAtTimestamp which is an internal property, in the latest v6.1.1 on MyGet I’ve added the LastConnectedSecs public property to make it easier.